
Predicting Term Deposit Subscriptions
Personal Project
Project Type:
Classification Modeling, Predictive Analytics, Customer Behavior Analysis, Machine Learning, Python
Date:
GitHub Repo:
Project Description
Banks often rely on telemarketing to promote term deposits, but these campaigns tend to be inefficient, with conversion rates hovering around 10%. This project investigates how customer characteristics, contact methods, and call behaviors impact subscription rates using a real world dataset of over 45,000 interactions. By identifying which factors most influence subscription decisions, this analysis helps the marketing team optimize targeting, reduce wasted calls, and improve customer experience.
Executive Summary
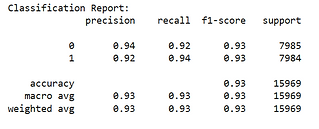
The Random Forest model was selected for deployment due to its performance achieving 94% accuracy and an AUC of 0.99, making it highly effective at distinguishing between subscribers and non-subscribers.
The most important factor was call duration: longer calls significantly increased the likelihood of a successful subscription. Other key variables included the method of contact, time since last contact, and customer job and marital status.
This analysis enables banks to:
-
Prioritize longer, engaging calls for likely subscribers
-
Refine outreach strategies by contact channel
-
Avoid oversaturating customers with repeated calls
-
Personalize messaging based on demographics
By applying these insights, marketing teams can optimize campaign efficiency, reduce wasted calls, and increase customer conversions.
Deep Dive
The dataset, sourced from a Portuguese bank, included over 45,000 telemarketing campaign records. Each record captured customer demographics (e.g., age, job, marital status), call metadata (e.g., duration, contact method), and outcomes from previous marketing efforts. The target variable indicated whether a customer subscribed to a term deposit, with only ~10% positive responses, highlighting a significant class imbalance that influenced model selection.
Exploratory Data Analysis
Exploratory analysis helped uncover important trends and potential modeling signals.
A few key observations:
Class Imbalance: Only ~11% of customers subscribed to the term deposit, confirming a need to monitor precision and recall during modeling.


Call Duration: Longer calls seems to correlate with higher subscription likelihood.
Subscription Rates by Contact Method: Cellular contact method has the highest total count of customer interactions and has the highest subscriptions..


Monthly Variations in Subscription Rates: May, July, and August witness the highest subscriptions, while, December and March have the lowest. March is the only month with slightly more subscriptions than non-subscriptions.
Preprocessing & Feature Engineering
Encoding was applied to convert categorical variables into a format suitable for modeling. Categorical features such as job, contact method, and education were one-hot encoded to allow the model to interpret them numerically. The target variable y, indicating whether a customer subscribed, was label encoded (0 for "no", 1 for "yes"). Additionally, a binary flag (was_contacted_before) was created based on the pdays column to indicate if a customer had been contacted previously, helping capture recency of outreach.

Modeling
The data, based on subscriptions, is very imbalanced (~11% subscribed from a call). This influences our modeling, so before modeling, I applied SMOTE and it had improved the modeling results from the original attempt.
SMOTE(Synthetic Minority Over-sampling Technique) generates synthetic examples of the minority class by interpolating between existing ones (Chawla et al., 2002), helping the model learn meaningful patterns without simply duplicating data.
The models I chose to test were:
-
Logistic Regression: Used as a baseline for interpretability.
-
Random Forest: Provided better handling of non-linear relationships and variable importance.
-
XGBoost: Tuned for performance and comparison.
Random Forest was selected as the final model, achieving:
-
Accuracy: ~94%
-
ROC AUC: ~0.99
-
Balanced precision and recall, effectively distinguishing both subscriber and non-subscriber groups.
Cross validation was done and there seemed to be no overfitting.

Final Thoughts
Top 5 Features Influencing Subscriptions:
Call duration is the most important feature, telling us duration heavily influences subscription outcome.

Key Findings
-
Call Duration is the Top Driver: Longer conversations increase the likelihood of subscription based on feature importance.
-
Contact Method May Matter: Calls labeled as “unknown” had the lowest engagement. This may call for improvement with data collection.
-
Previous Contact History (pdays): Customers contacted recently were less likely to convert.
-
Seasonal Variation in Conversions: May, July, and August had peak success rates.
-
Customer Demographics Play a Role: Marital status and housing status influence conversion likelihood based on feature importance.
With this model, the business can predict the probability of a call ending in subscription. Possibly aiding in training of callers and campaign improvements.
Recommendations
-
Agent Strategy: Extend call durations to increase engagement without sounding scripted.
-
Channel Optimization: Avoid “unknown” contact methods. Focus on channels with high ROI by investigating why certain contact methods work better and shift focus to more effective communication channels.
-
Frequency Management: Respect customer contact fatigue; stagger outreach strategically.
-
Seasonal Timing: Launch major campaigns in high-conversion months (May, July, and August).
-
Targeting Strategy: Personalize marketing approaches based on demographic insights to improve customer targeting.
Citations
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002).SMOTE: Synthetic Minority Over-sampling Technique.Journal of Artificial Intelligence Research, 16, 321–357.https://doi.org/10.1613/jair.953
Moro, S., Rita, P., & Cortez, P. (2014). Bank Marketing [Dataset]. UCI Machine Learning Repository. https://doi.org/10.24432/C5K306.
Thank you! Please message any suggestions.